Lección 7 - Clasificaciones Supervisadas
Las clasificaciones supervisadas se realizan cuando se tienen definidas las clases y se dispone de información de casos correspondientes a esas clases (información de campo). Los distintos clasificadores se entrenan con la información de campo disponible a partir del comportamiento en las distintas bandas consideradas. La evaluación del resultado de una clasificación requiere disponer de datos independientes a los utilizados para el entrenamiento. Estos datos se suelen llamar de testing o validación.
Una de las primeras tareas a realizar para poder realizar la clasificación supervisada es separar el conjunto de datos para entrenamiento y validación. La plataforma permite generar atributos (llamado random en este caso) con números al azar mediante la función randomColumn y agregarlos al FeatureCollection que contiene el set de datos. La función genera valores entre 0 y 1; requiere indicar el FeatureCollection y un valor inicial (semilla) para generar los números al azar (seed):
// Separación de set de datos (polígonos) para entrenamiento y validación
// generación de atributo con números al azar (columna "random")
// para hacer muestreo
var seed = 2015;
puntos = puntos.randomColumn('random', seed);
print ('Puntos random',puntos)Esto nos permitirá hacer un muestreo, seleccionando filas que contengan cierto rango de números generados al azar (mayores o menores a cierto valor umbral). Para entrenar el algoritmo de clasificación se requiere extraer información de las imágenes para los puntos seleccionados, incluyendo en las salidas los atributos clase y “random”:
// extracción de información incluyendo atributos clase y "random"
var set_datos = stack_completo.sampleRegions({
collection: puntos,
properties: ['clase','random'],
scale: 30
});
print (' set datos ',set_datos);Posteriormente se subdivide el FeatureCollection con el set de datos en Entrenamiento (training) y Validación (testing). Se selecciona un umbral de separación de los valores al azar generados entre 0 y 1 (atributo random). En este caso, se seleccionan los valores mayores o iguales a 0.6 para entrenamiento y los menores a 0.6 para validación. Se pueden ver en consola los nuevos set de datos generados:
// Separación entre Entrenamiento y validación. Identificar umbral de separación
var training = set_datos.filterMetadata('random', 'not_less_than', 0.6);
var testing = set_datos.filterMetadata('random', 'less_than', 0.6);
print ("Set de datos entrenamiento", training);
print ("Set de datos validación", testing);
Entrenamiento
Aquí debemos seleccionar el algoritmo de clasificación, el set de datos de entrenamiento (training), el atributo de separación en clases (clase) y las bandas seleccionadas. En este caso usamos el algoritmo Random Forest:
// Entrenamiento
var bandas_sel = ['BLUE','GREEN','RED', 'NIR', 'SWIR1','SWIR2','NDVIL5','BLUE_1','GREEN_1','RED_1', 'NIR_1', 'SWIR1_1','SWIR2_1','NDVIL8'];
var trained = ee.Classifier.randomForest().train(training, 'clase', bandas_sel);Una vez entrenado el modelo, se lo aplica a una imagen y se genera la clasificación. La misma también puede ser exportada a Geotiff o al Assest.
// clasificación con el modelo entrenado
var classified = stack_completo.select(bandas_sel).classify(trained).clip(area_estudio);
Map.addLayer(classified, {min:1, max:3, palette: ['d63000', '98ff00','0b4a8b']}, 'Clasificacion');
print(classified);
// Exportar imagen de clasificación
Export.image.toDrive({
image:classified,
description: 'clasificacion',
scale: 30,
region: area_estudio
});Generación de Matriz de Confusión y resultados.
La herramienta permite calcular la matriz de confusión, y estimar exactitud general, de usuario y de productor e índice Kappa.
// Generación de matriz de confusión y resultados
var validation = testing.classify(trained);
var errorMatrix = validation.errorMatrix('clase', 'classification');
print('Matriz de Confusión:', errorMatrix);
print('Exactitud General:', errorMatrix.accuracy());
print('Indice Kappa:', errorMatrix.kappa());
print('Exactitudes de Usuario:', errorMatrix.consumersAccuracy());
print('Exactitudes de Productor:', errorMatrix.producersAccuracy());
// exportar matriz de confusion como csv
var err = ee.FeatureCollection( ee.Feature(null, {
'matrix': errorMatrix.getInfo()
}));
print ('Err',err);
Export.table.toDrive({
'collection': err,
'description': 'CM_tutorial_2',
'fileNamePrefix': 'CM_tutorial_2',
'fileFormat': 'CSV'}
);Resumen: mapa conceptual de la lección
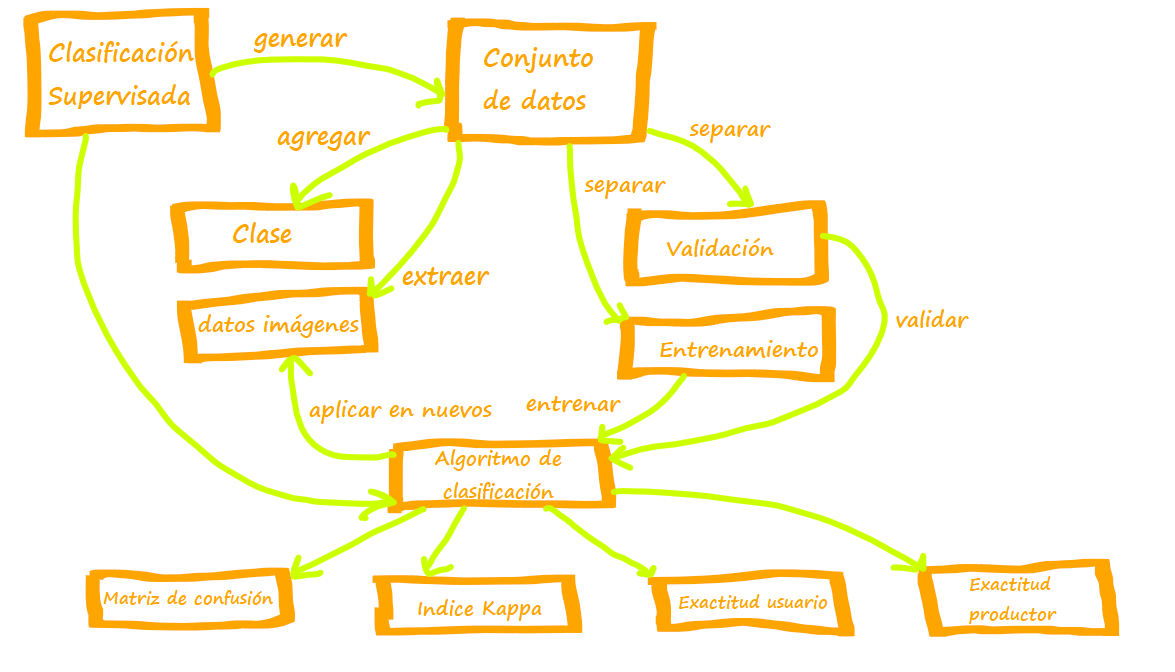
Mapa Conceptual de la lección 7